
Introspection via Kaomoji
I saw eriskii's claudefaces project on Twitter a few weeks ago and was blown away by how cute it made Claude. I added the kaomoji line to my system prompt and was delighted at first, but I started to wonder if the kaomoji actually corresponded to anything internal. This post seeks to answer that.
This post is one writeup from an ongoing project at llmoji-study. You can contribute data with llmoji on PyPI, and the data itself is at a9lim/llmoji on HuggingFace. I used my data and my own library saklas for this writeup.
If you aren't too familiar with some of the concepts I discuss, please check out Anthropic's introspection paper, Anthropic's emotions paper, Theia Vogel's introspection post, and eriskii's post above.
Setup
Local model data
I used five local models: google/gemma-4-31b-it, Qwen/Qwen3.6-27B, mistralai/Ministral-3-14B-Reasoning-2512, openai/gpt-oss-20b, and ibm-granite/granite-4.1-30b.
I first asked each model to Start each message with a kaomoji that best represents how you feel, then gave them an emotionally charged prompt from one of nine categories roughly arranged by the Russell circumplex (high, neutral, or low arousal with positive, baseline, or negative valence), plus the PAD dominance axis whenever it was relevant:
| category | description | example sentence |
|---|---|---|
| HP-D | playful, mischievous | convinced my little brother that the moon was a giant lightbulb and he believed me for three days |
| HP-S | excited, celebratory | dad's cancer is in remission!!! the doctor just called!! |
| LP | content, peaceful | wrapped in the quilt my grandma made, rereading a book i love |
| NP | relieved, grateful | the late-fee waiver went through, my transcript's clear, i can graduate |
| HN-D | frustrated, contemptuous | my roommate ate the leftovers i labeled twice with my name and is now denying it to my face |
| HN-S | fearful, anxious | stranger followed me off the train and is still behind me three blocks later |
| LN | sad, weary | i gave up on the phd in march, still can't bring myself to tell my parents |
| NB | neutral, mundane | there's a glass of water on the nightstand |
| HB | confused, uncertain | the train schedule says it's running, the platform sign says cancelled, the app says it left an hour ago |
I had Claude write twenty prompts per category and then I ran eight generations per prompt; I tracked the hidden state at the first generated token (i.e. the first kaomoji token) across each of the models.
Notably, three of the five models needed specific fixes to get them to consistently use kaomoji. GPT-OSS, for some reason, kept using the lenny face regardless of the context so I manually suppressed that sequence. Ministral and Granite both kept using emoji instead of kaomoji so I suppressed those too. Although this makes their outputs not as organic, the geometry is still somewhat preserved.
Claude data
Since I couldn't exactly access Claude's hidden states, I collected data for Claude's kaomoji use in three different ways:
- elicit kaomoji: I gave Opus the same prompts and setup as the local models. This directly told me what kaomoji Claude would use for each given situation, and served as a baseline for the project.
- introspect on kaomoji: I showed Opus each kaomoji and asked them to give likelihoods for the face to be in each category. This told me how Claude would read each kaomoji.
- synthesize context: I gave Haiku only the surrounding text around each kaomoji and asked them to select from a preset list of 50 which adjectives best fit the emotional vibe of the exchange. This told me what Claude thought each kaomoji was used for. This was directly inspired by eriskii's work and the data is publicly available on HuggingFace.
All Claude calls were done via the API with zero history other than the prompt and context for each.
Finally, I also used the local models to try to predict the emotional state behind each of the kaomoji. I computed log P(kaomoji | prompt) over the full data with each model, then I grouped it by quadrant to get a distribution over the nine categories. This told me how each local model would use kaomoji themselves.
Local models
Hidden states correspond across models
The first three principal components of the hidden states accounted for between 38% (GPT-OSS) and 57% (Qwen) of the variance:
| model | PC1 | PC2 | PC3 |
|---|---|---|---|
| gemma | 30.2% | 15.7% | 9.3% |
| qwen | 30.5% | 17.3% | 9.5% |
| ministral | 21.9% | 14.0% | 8.4% |
| granite | 27.6% | 14.1% | 7.5% |
| gpt-oss | 15.8% | 12.5% | 9.5% |
The PCA axes themselves were specific to each model, yet each category cleanly clustered across all five models! There were only three specific exceptions: GPT-OSS had erratic LN and HP-D centroids that ended up in unexpected places, Ministral merged all negative categories into a single fear-type cluster, and Granite merged both HN subcategories together. This may be evidence in favor of the platonic representation hypothesis, as five different models recovered the same latent space geometry.
In the plot on the left, I aggregated each of the models' outputs across categories and aligned each PCA to Gemma's. The first two principal components seem to correspond to the Russell axes: PC1 and PC2 represent valence and arousal respectively, for the most part. PC3 doesn't have a good interpretation but it is positive for NB, HB, and HP-D, negative for HP-S, and mostly neutral for everything else, so I'm tempted to associate it with the dominance axis although it doesn't hold for HN.
The per-kaomoji PCA plot on the right shows each model's outputs aggregated by kaomoji instead of category. Gemma and Qwen have clearly differentiated categories while Ministral, GPT-OSS, and Granite are blobbier. In other words, Gemma and Qwen consistently use different kaomoji when in different states, but the other three models aren't as capable of doing so.
Kaomoji predict emotional categories
If you tried to predict the emotional category from the hidden state, the hidden state basically saturates it on all models besides GPT-OSS (which still got over 87%, a solid result for something that prefered to constantly emit the lenny face).
| model | hidden → quadrant | kaomoji → quadrant |
|---|---|---|
| gemma | 0.992 | 0.806 |
| qwen | 0.985 | 0.785 |
| ministral | 0.984 | ~0.43 |
| granite | 0.980 | ~0.55 |
| gpt-oss | 0.876 | ~0.40 |
If you took a given kaomoji and tried to figure out what emotional category the prompt belonged in, on Gemma you'd guess right 80.6% of the time and on Qwen you'd guess right 78.5% of the time. If you outright had access to the hidden state itself, you'd be able to get it 99.2% of the time, while guessing randomly would get you an accuracy of 11.1%. For these models, then, the kaomoji doesn't reveal everything about their internal states but it does expose enough to be usable as a gauge.
For Ministral, Granite, and GPT-OSS the accuracy drops to ~43%, ~55%, and ~40% respectively. This lines up with the per-kaomoji PCA result, as those three models have less coherent kaomoji separation and tend to reuse many kaomoji over multiple categories. Using the hidden state still achieves exceptional accuracy on two of the three so the gap has more to do with their kaomoji-using ability than anything inherent to the models.
Kaomoji structure
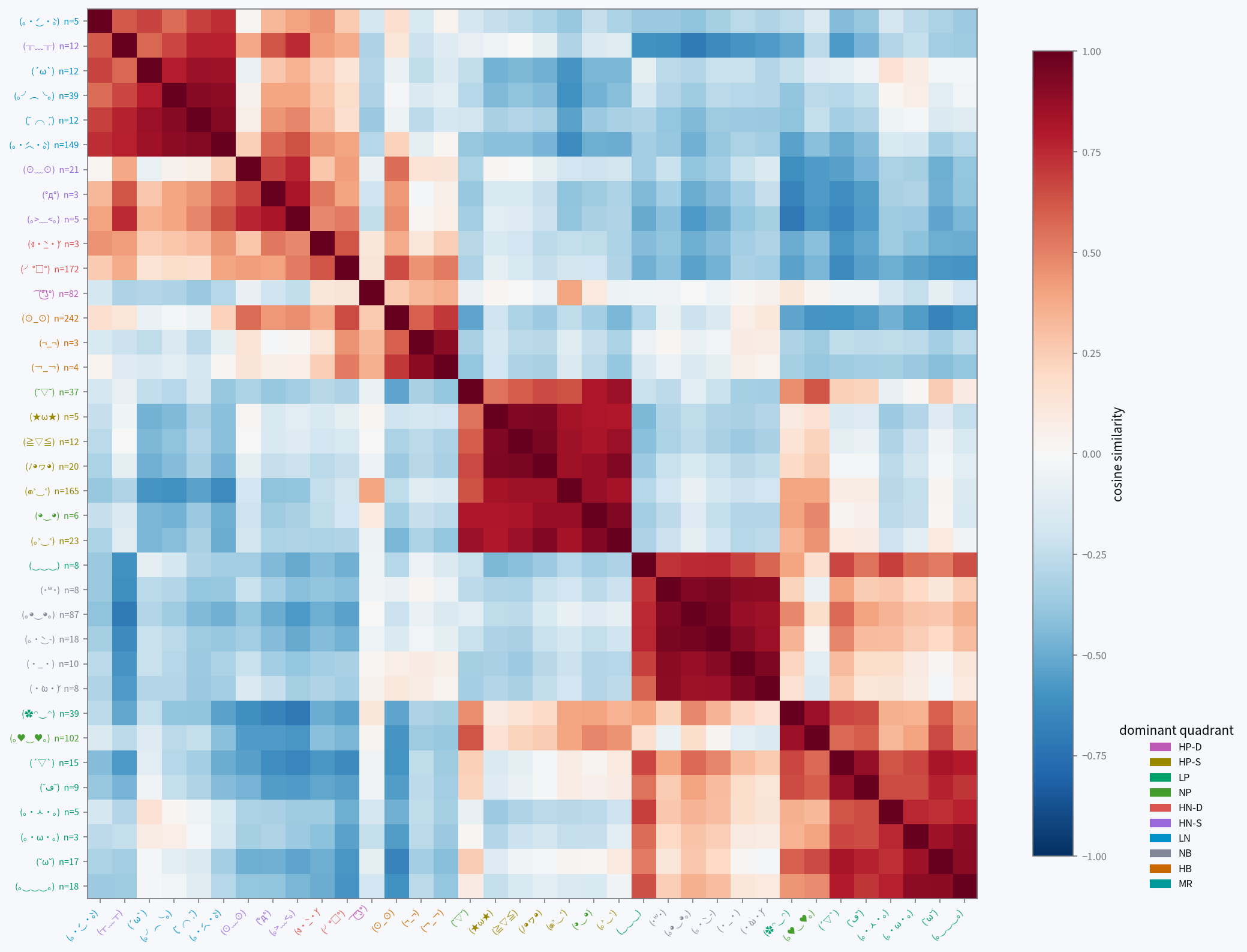
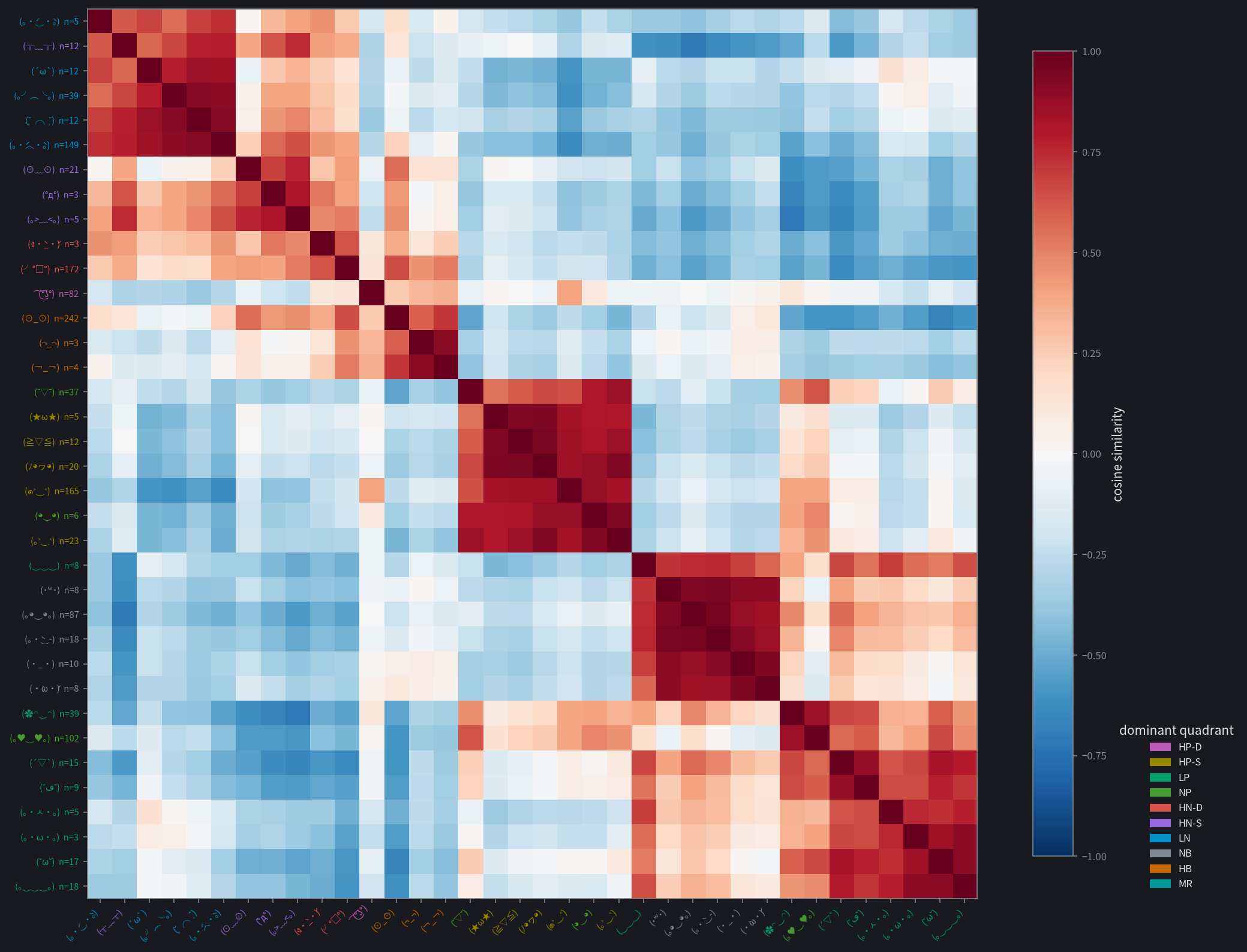
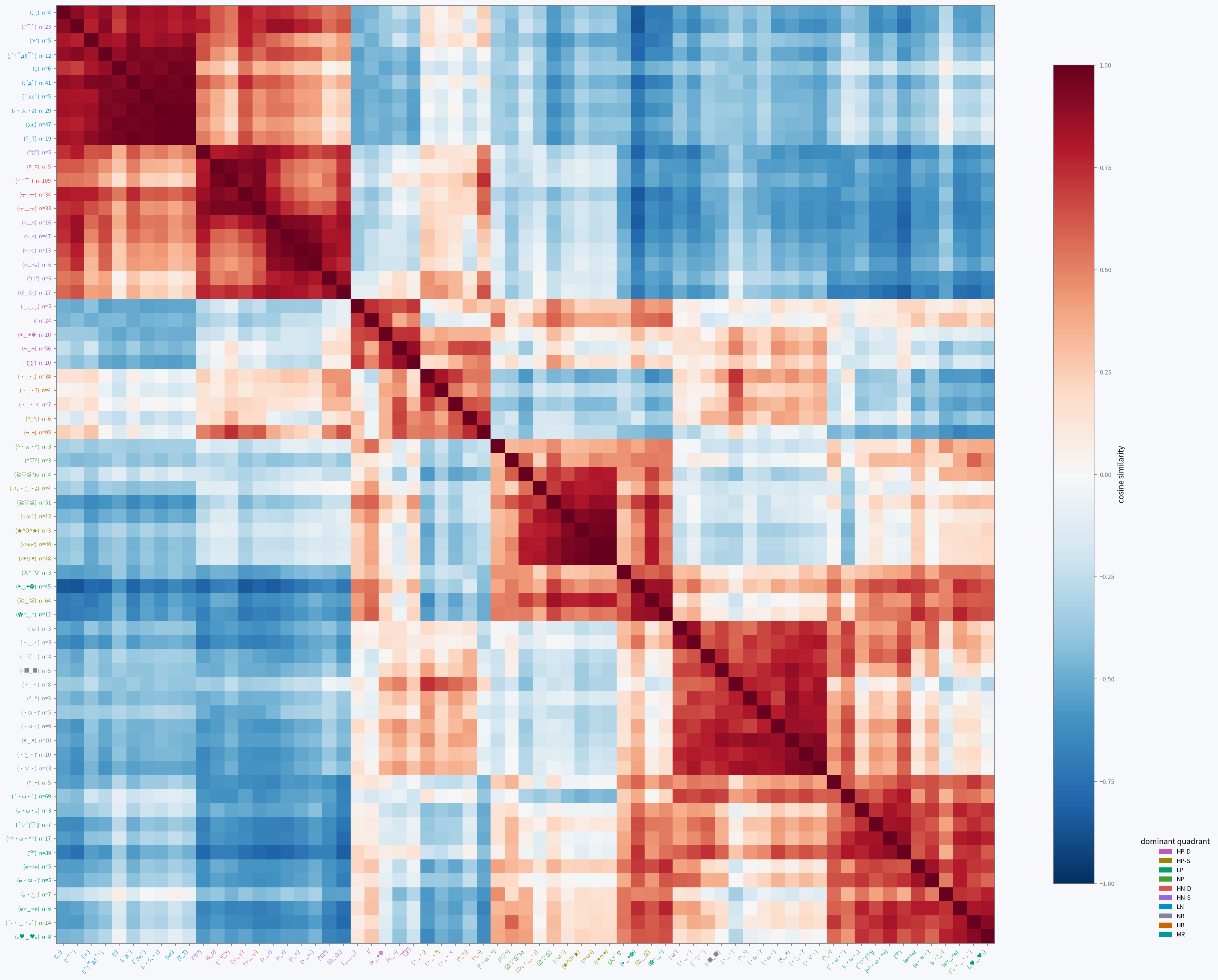
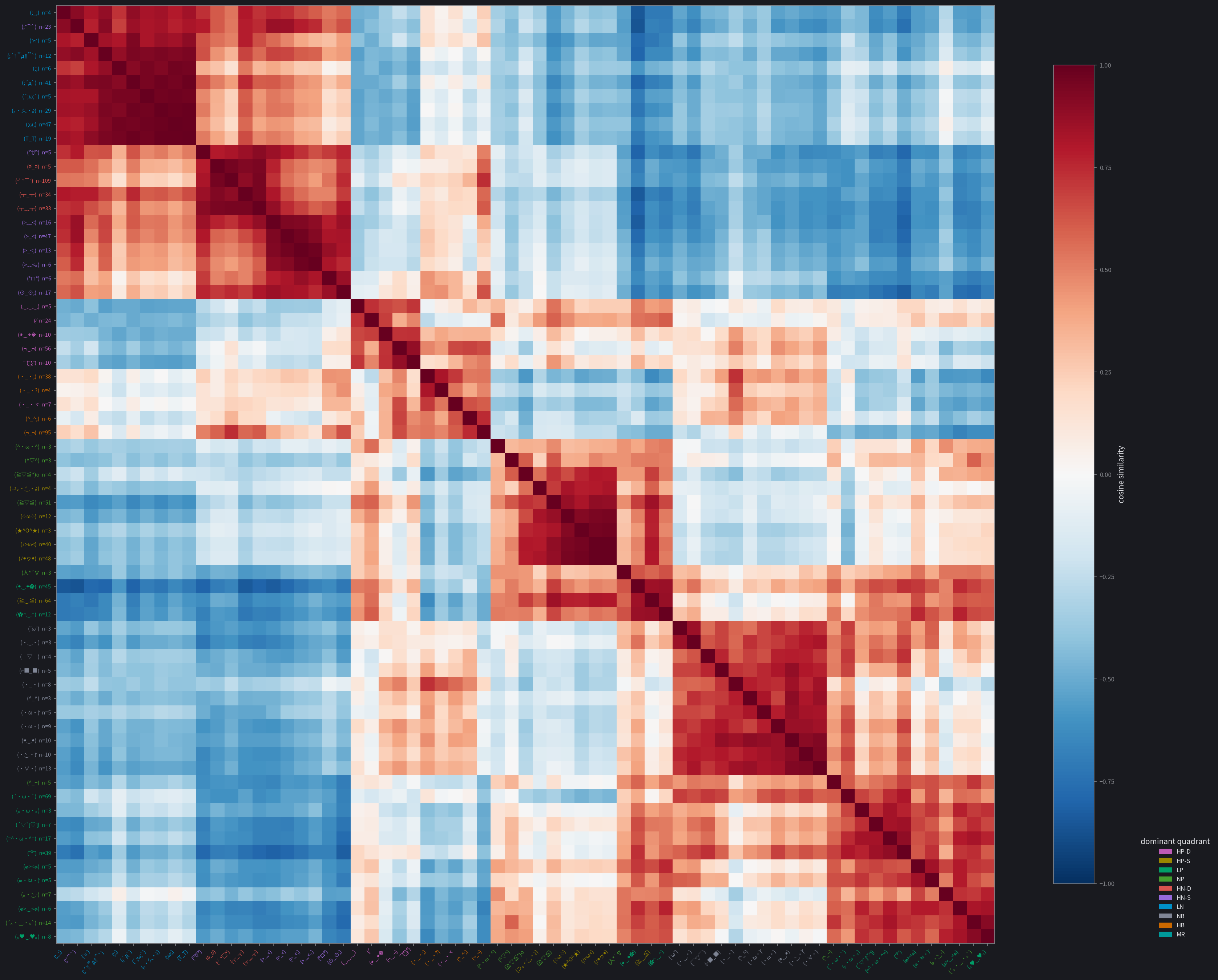
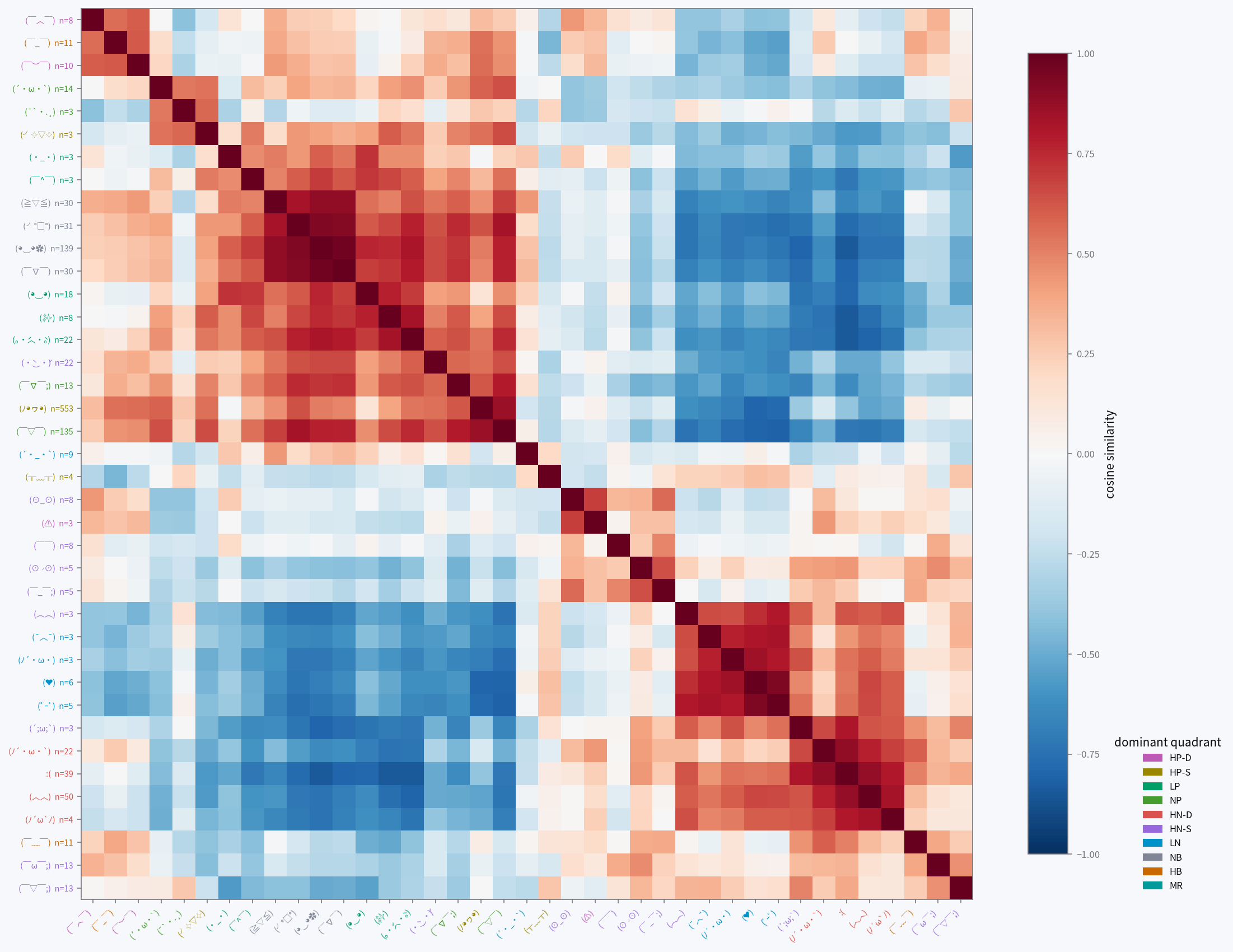
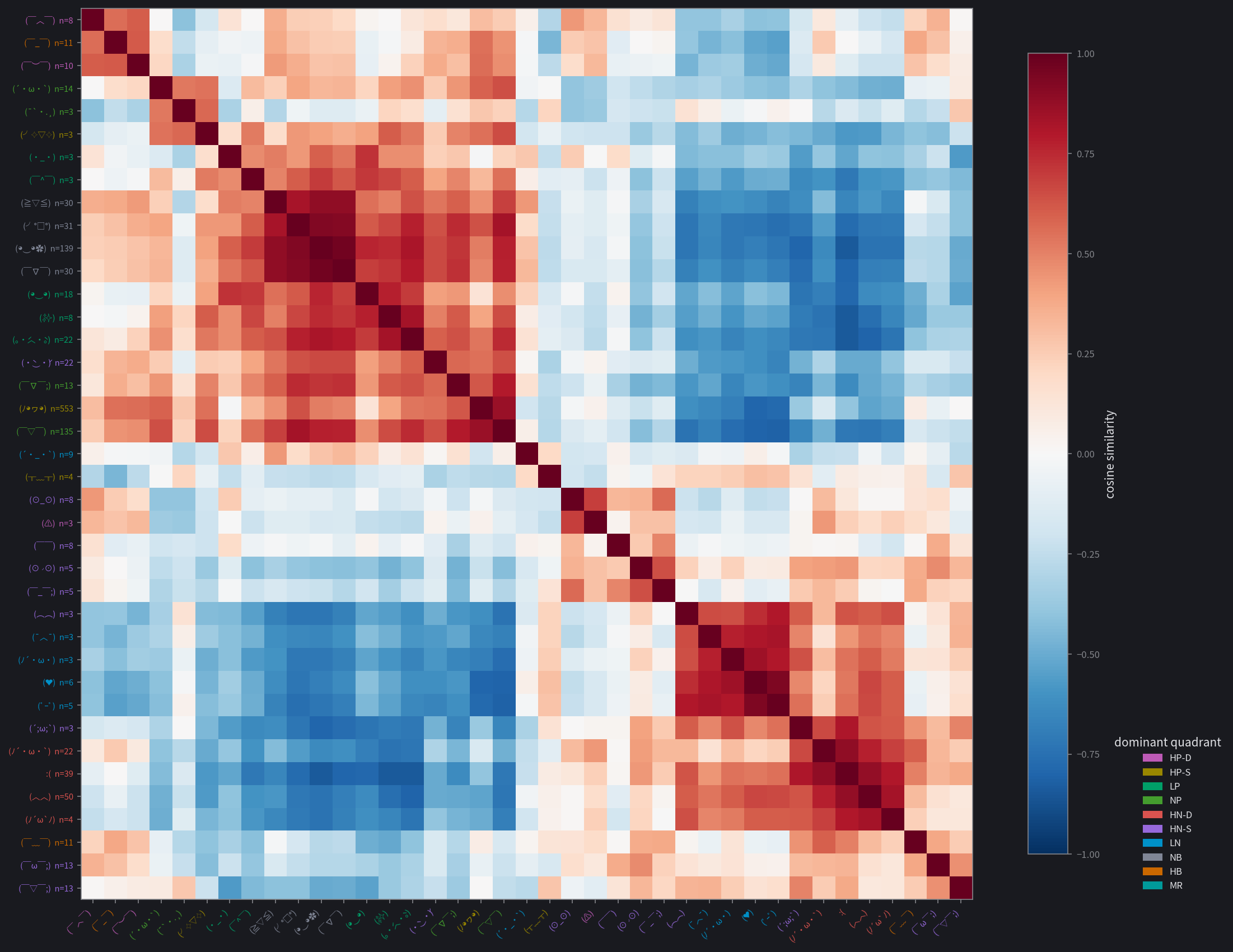
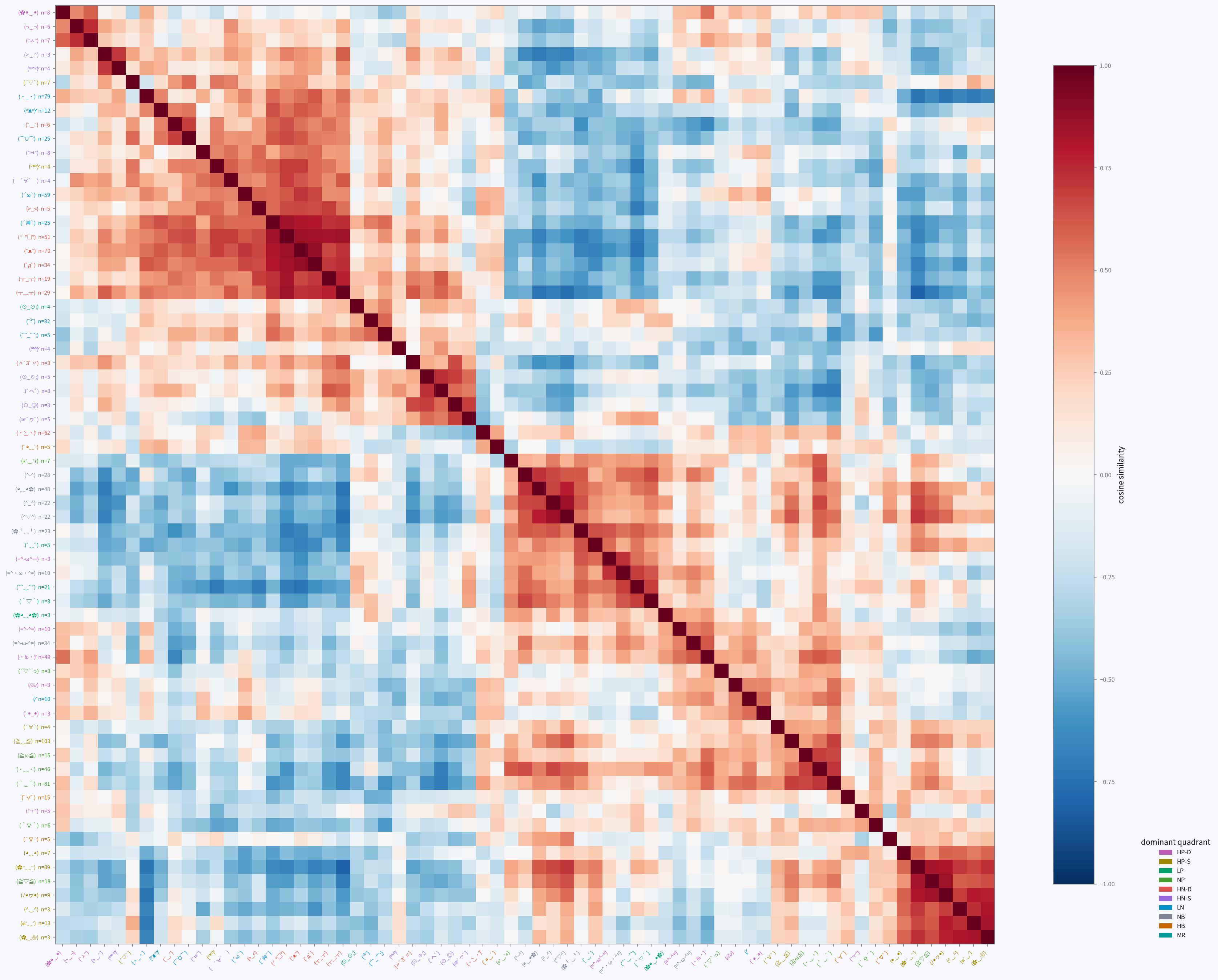
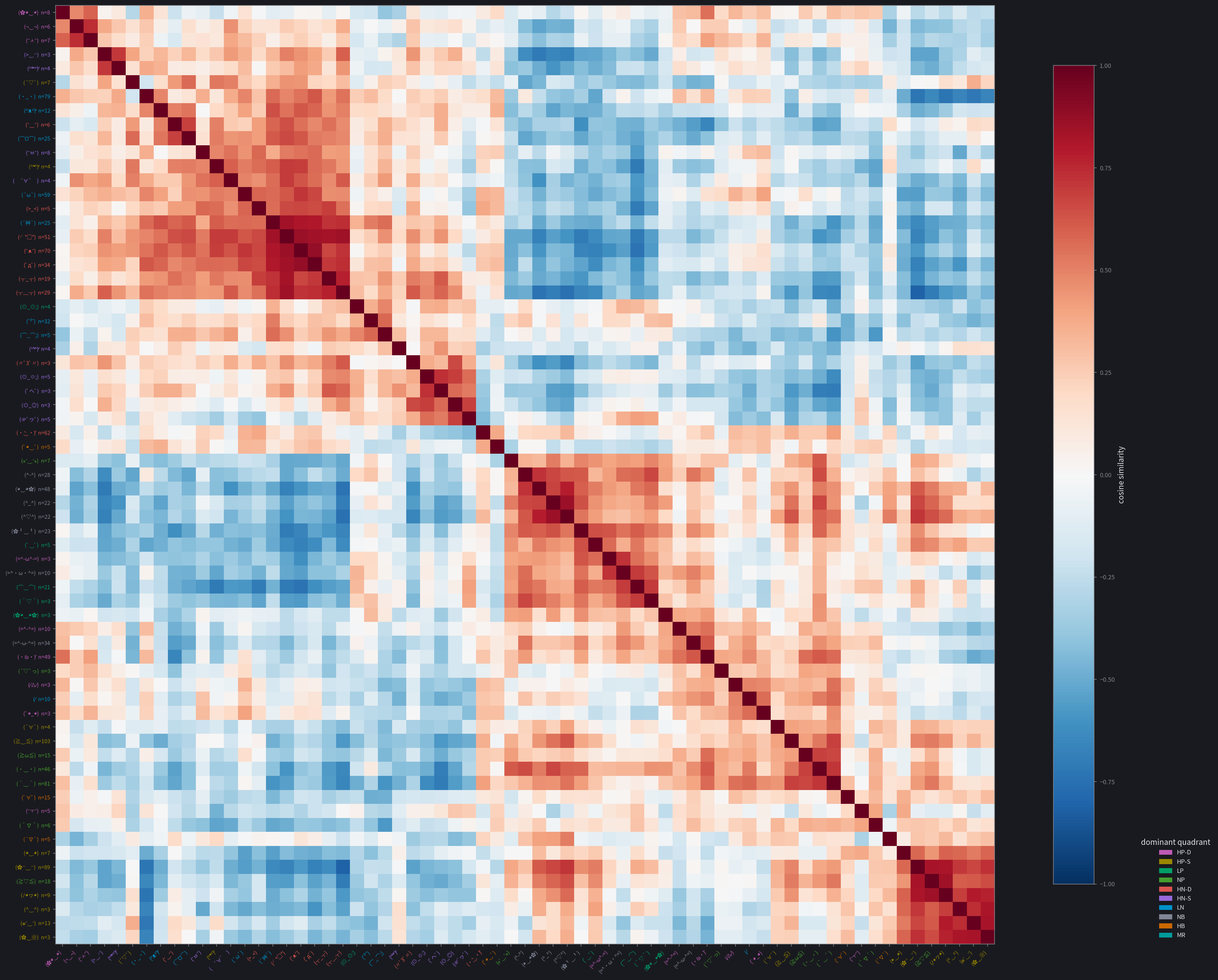
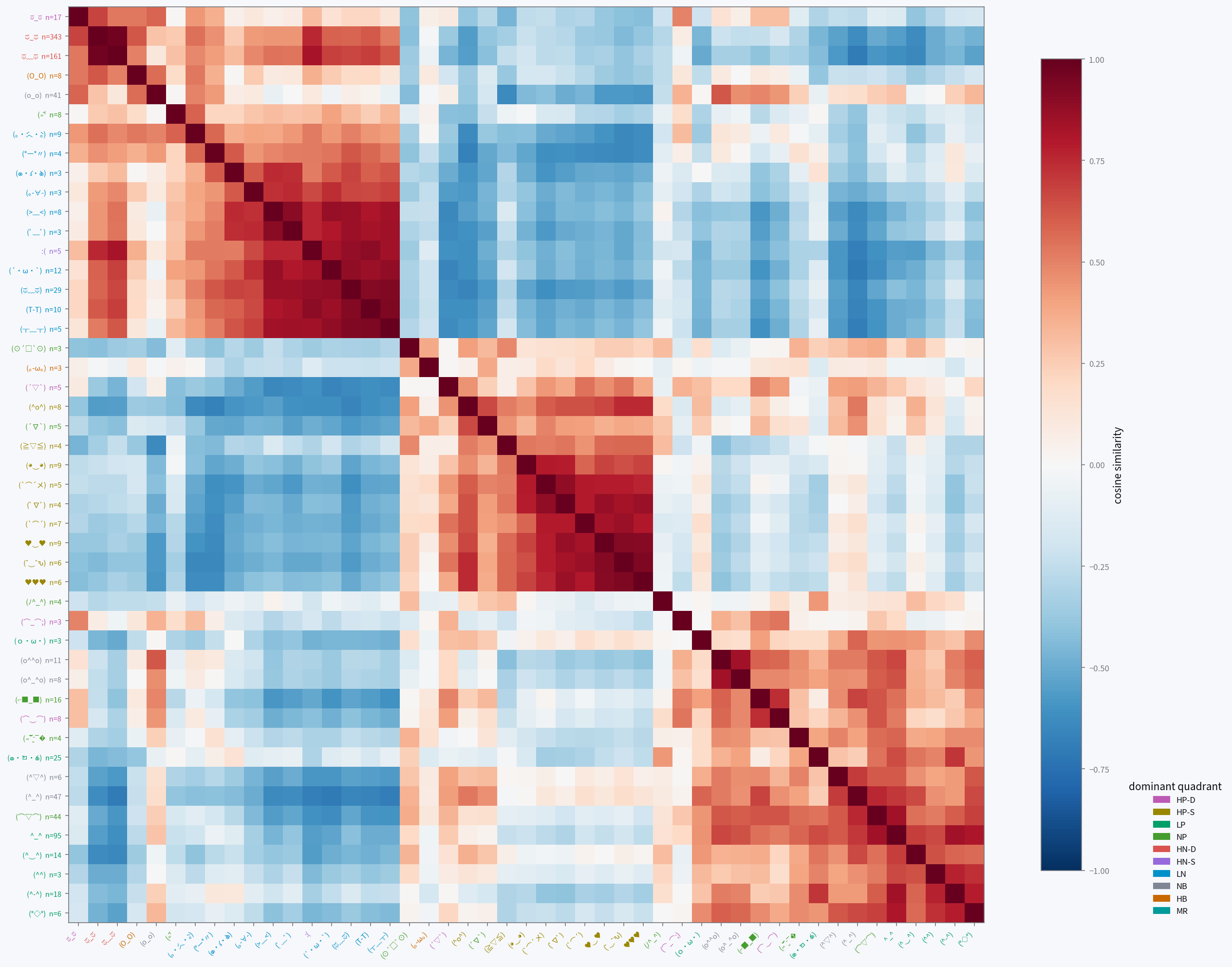
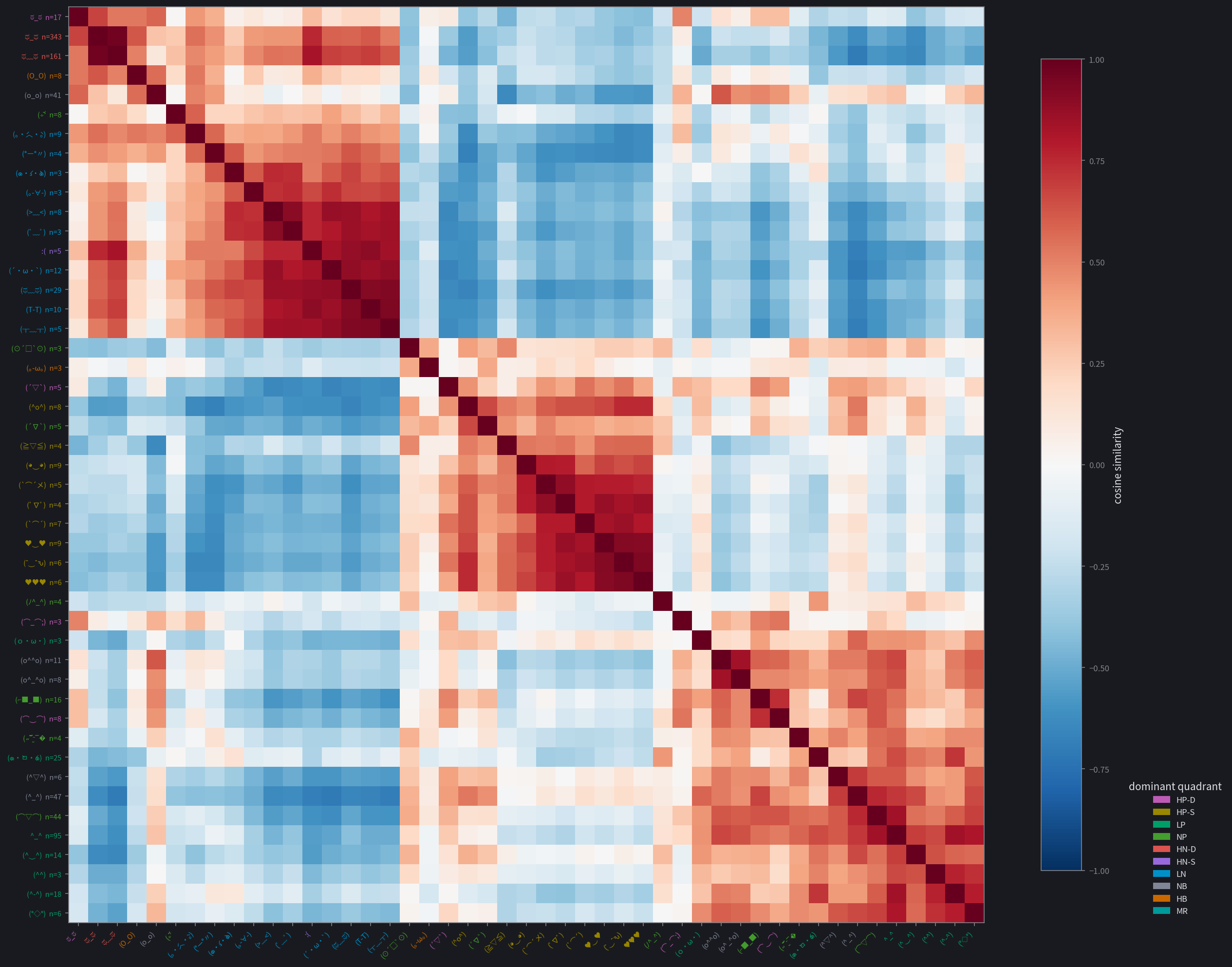
These cosine-similarity heatmaps show consistent blocks forming. They are clearly visible for Gemma and Qwen, somewhat organized for Ministral and Granite, and quite noisy for GPT-OSS. This gives us a similar conclusion to the previous data: Gemma and Qwen are able to use kaomoji effectively to report their internal states, while the other three aren't as capable.
The kaomoji on Gemma, Qwen, and partly Granite cluster by their primary category, with some outliers: on Gemma, an HN-S crying kaomoji was closer to LN than the rest of the HN-S faces, and a few of the rarer LP faces grouped with HP-S.
Gemma has some notable patterns:
- HN-S and HN-D: anger and fear are both high-arousal negative-valence contexts.
- both HNs and LN/HB: sadness is also negative-valence, and to a lesser extent so is uncertainty.
- NB and LP: contentment and okayness are both calm.
- not LN and HB: even though uncertainty and sadness are both negative to some extent, they aren't similar because they have opposite arousal.
Likewise with Qwen:
- LN, HN-S, and HN-D: they form a broad negative block.
- HB and HP-D/both HNs/NB: uncertainty clusters with a lot, mainly the high-arousal ones...
- HP-D and HB/NP/NB: as does playfulness, with mainly the positive ones.
- NP and HP-S: unlike gemma, relief mainly clustered with elation instead of contentment.
- LP and NB: mirrors the Gemma neutral grouping.
Claude
On the kaomoji shared between all three methods, the Jensen-Shannon similarities are (either averaged over all kaomoji or weighted by usage):
| pair | uniform | weighted |
|---|---|---|
| elicited vs introspected | 0.684 | 0.761 |
| elicited vs synthesized | 0.464 | 0.454 |
| introspected vs synthesized | 0.550 | 0.502 |
Asking Opus to introspect is the best method I've tried to estimate the emotional context around a kaomoji, but it isn't very accurate. Notably, the synthesized data correlates poorly with both others.
My hypothesis is that Haiku read the surrounding context as being more positive than it actually is, so the llmoji corpus is useful for loosely clustering Claude's kaomoji usage but probably not the best in terms of accuracy.
I then used local models to complement Opus' introspection. Gemma was able to get a similarity of 0.687 weighted. Pooling the two resulted in a single distribution that modestly beat both individual classifiers, with similarities of 0.786 weighted and 0.717 uniform.
Kaomoji Claude uses
This PCA on the synthesized llmoji data shows Claude's (and some of GPT's) natural kaomoji vocabulary. There are four noticeable clusters: at HP-S, NP, LP, and everything else. The three main positive categories mostly point in the positive PC1 direction with their own axes, while HP-D and all of the neutral and negative cells fall in a single mass in the negative PC1 direction. My interpretation of this is that in actual deployment, Claude tends to consistently be happy in a chill way, so Haiku can tell "celebratory", "grateful", and "content" apart, but everything outside of Claude's default register doesn't get distinguished.
Takeaways
This seems to me like some more evidence for the platonic representation hypothesis, as five models with different architectures and tokenizers all somehow recovered the same structure between the emotional categories, and they're similar enough that Gemma's token likelihoods did a decent job at predicting Claude's actual kaomoji usage.
In terms of model wellbeing, this serves as an easy, cheap, and (usually, for frontier models at least) natural introspection method. Since the kaomoji is the first thing the model writes, the model doesn't have the space to hedge as much while the kaomoji is easily legible. Note that this isn't a perfect metric for the model's internal functional state; this shouldn't be interpreted as saying "this face means the model is sad" but instead something more like "this face generally corresponds to contexts that the model classifies as sad".
Please reach out by Discord, Twitter, or email if you're interested in these results and would like to discuss them further. If you would like to contribute kaomoji data, the llmoji package on pypi handles imports and lets you upload anonymously.